Author: L.S.Lowe. File: raidperf24. Original version: 20120723. This update: 20130104. Part of Guide to the Local System.
The RAID for this series of tests is an Infortrend EonStorDS ESDS S24S G2240, equipped with 24 Hitachi disks (3TB, SATA, 7.2k, HUA723030ALA640), and 2 GB of RAM buffer memory, to be set up with 2 RAIDsets of 12 disks each configured as RAID6, and so with the data equivalent of 10 disks each (30 TB of real data). The RAID stripe size will be kept at the factory default: 128 kiB. I have three of these currently, all to be deployed at the same time. For my earlier Infortrend RAIDs, see my local Guide (linked above).The Infortrend brochure says that this ESDS S24S-G2240 is equipped for host connectivity with two 6Gb/s SAS 4x wide ports, without any host-out ports, and, for an expansion enclosure, one 6Gb/s SAS 4x wide port. I interpret this as meaning peak transfer rate of 24 Gbit/sec, that is 3 GByte/sec, per port. (There are alternative four host-port and dual controller versions).
The HBA card used to connect the RAID to the Dell R710 host was an LSI SAS 9201-16e full-height half-length card (part number LSI00276) which uses PCI-Express x8 (generation 2) bus. PCI-Express x8 G2 has a theoretical performance of 5 GT/sec or 500 MBytes/sec per lane, so a theoretical 4 GBytes/sec.
When re-deploying one of the RAIDs (f25) later, the HBA card used to connect the RAID to a Dell R710 host was an LSI SAS3801E low-profile half-length card (part number LSI00138). This operates on a 3Gb/s link 4x wide port, so I understand this to be a peak transfer rate of 12 Gbit/sec, that is 1.5 GByte/sec, per port. It also uses PCI-Express x8 G2. The RAID performance with this lower-spec card was found to be equally good, see results below, so wasn't a limiting factor in its read or write performance.
One of the Infortrend units had been delivered with firmware level 3.86C.09, and two with 3.86C.11.
A clone operation of an individual disk drive can be done if it's failing, and if you have a spare drive in the unit to copy it to. To do 5% took around 16 minutes, 45% took 2h35m, so that's about 5h44m to do the complete copy. This works out as around 145 MBytes/second, close to the 157 Mbyte/sec official individual sustained transfer speed of these particular Hitachi drives.
To test re-build time, I needed to simulate a disk failure, so I removed a drive from an existing 12-disk RAID-6 logical drive which was part of an online logical volume, while it was not busy. After a couple of minutes I replaced it, but it was marked EXILED, so I needed to clear that status for this perfectly good drive. It should be possible to do this by clearing the disk reserved area. I couldn't do that on the unit itself, oddly, because the unit was sufficiently busy with the EXILED drive that the password for enabling that operation was cleared several times before I was able to enter it in full! Maybe if I'd used the web GUI, I'd have had more success. Anyway, I cleared the reserved area successfully using another RAID with spare slots. Having re-inserted the cleared drive into its original RAID slot, it was then accepted as a fresh drive, and re-building started. I noted that the configuration disk array parameter Rebuild Priority was set to Normal, as on my previous Infortrend arrays. This presumably only affects relative priority of rebuild versus host-I/O activity, so where there is no host activity, its setting has no likely effect.
Rebuilding reached 1% after 10 minutes, 10% after 54 minutes. The full rebuild time was 8h36m for this 12-disk 3TB RAID6 array.
I had seen that the firmware levels on the other two RAIDs was out of step, and that also there was more recent firmware available from Infortrend, so I decided with Infortrend's help to update to the latest recommended level at the time: 3.88A.03. Before doing this I deleted the logical drives already created so that new logical drives could be created with any benefits of the new firmware.
I've checked on another similar RAID that this does not depend on whether the initialisation is done in Online or Offline mode: in the situation where there is no host activity, I wouldn't expect a difference anyway. Also I did a Restore Defaults using the button at the back, which is like a Factory Reset: this cleared the password and the unit name that I had set, but didn't help with restoring a sane initialisation time. (Later on I also did a clear of all logical drives and removal of all drives reserved areas, see firmware section below, and started again, but this didn't help either). Also I checked that turning on Verification on LD Initialization Writes did make it take even longer (108m to do 2%, which extrapolates to 90 hours), so it's unlikely that the problem is due to verifies being done unsolicited. As you'd expect, all these tests were done with a Controller Reset (that is, a RAID reboot) after any config change, to have a clean start.
For a RAIDset of 12 drives in a RAID6: after 70 minutes, rebuilding had reached just 1%! The full rebuild-time was 60 hours 1 minute. This is to be compared with around 8.5 hours with the earlier firmware!
The time taken wasn't helped by the fact that installing an old version of firmware couldn't be done quickly via the web browser GUI, as this silently refused to accept earlier than current versions, so I ended up doing it via Hyperterm at the recommended speed of 9600 bits/sec, which takes two hours. Multiply that by the number of retries I needed to get the steps right!
My solution to getting a good working version of the Infortrend firmware was: remove all data on the drives by unmaking the Host LUN, deleting the logical volumes, and deleting the logical drives; remove the reserved area on every physical drive; power off; remove power leads for a minute; pull out every physical drive (half-way); replace power leads; power on with Restore Defaults button pressed; wait for initialisation; set a password; shutdown the controller (not a reset) to prepare for update; update the firmware via the serial port at 9600 baud using Hyperterm; allow reboot with Restore Defaults button pressed; push in every physical drive; create logical drives and volumes as required.
This may have been excessively elaborate, but certainly it was necessary to remove the reserved area on every drive (which is later automatically re-instated when the disks are made part of a RAIDset), in order to achieve the earlier firmware's good performance. Deciding if other steps are un/necessary I'll leave to others to discover!
Because of these shenanigans required for proper downgrading, I've only tested the 3.86C.09 and 3.88A.03 firmware versions for sure, and not the 3.86C.11 firmware which two of the RAIDs had been delivered with.
So I assigned Channel 0 ID 0 LUN 0 to LV0 Partition 0, and Channel 1 ID 0 LUN 0 to LV1 Partition 0.
These Partitions have nothing to do with the DOS or GPT partition that might (or might not) be created on the "disk" corresponding to the LUN, as seen by the host operating system.
When I subsequently attached the device to a server with an operating system, I found for me on that occasion with more than one LUN defined, that the order of the /dev/sdX device files, dynamically assigned at boot time, wasn't top to bottom in the RAID. There are probably various factors which could affect this (cabling, ordering of sockets on the LSI sas/sata HBA card, or presentation order by the RAID unit), but of course this is exactly why Linux uses filesystem LABELs and/or UUIDs, in order to eliminate ambiguities once the filesystems have been setup.
blockdev --setra command.
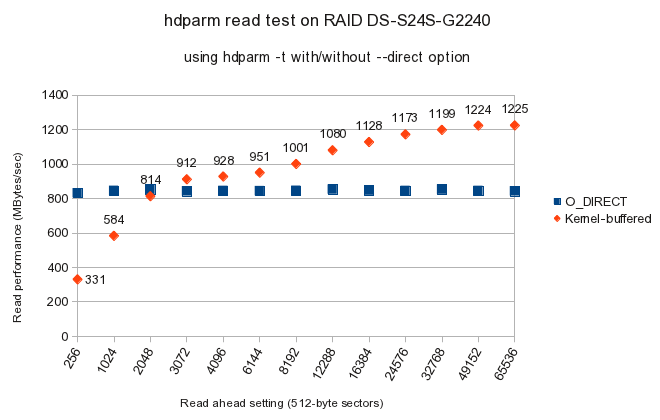
This gave the following results:
I formatted and mounted as the bare device, rather than as a GPT partition. (There was no real need for a GPT partition table, but if I did partition, it would be sensible to ensure that partition(s) begin on a RAID full-stripe boundary). I later found this useful XFS guide which confirms my mkfs.xfs parameters below:
# mkfs.xfs -f -d su=128k,sw=10 -L 24a /dev/xxx
meta-data=/dev/xxx isize=256 agcount=32, agsize=228880256 blks
= sectsz=512 attr=0
data = bsize=4096 blocks=7324168192, imaxpct=25
= sunit=32 swidth=320 blks, unwritten=1
naming =version 2 bsize=4096
log =internal log bsize=4096 blocks=32768, version=1
= sectsz=512 sunit=0 blks, lazy-count=0
realtime =none extsz=4096 blocks=0, rtextents=0
real 0m0.816s
user 0m0.002s
sys 0m0.016s
# mount LABEL=24a /disk/f24a
For the first setup, the system was booted with a kernel parameter of mem=4G in order to limit the amount of RAM available, as we wanted to measure the performance of the RAID, not of the Linux page buffer in RAM; a benchmark file space of 24 GiBytes was used, much larger than that RAM value; the bonnie chunk size was set as the RAID's per-disk stripe: 128 kiB. A second setup using the full RAM of 24 GiBytes and a larger file space of 48 GiBytes and a bonnie chunk size of 8 kiBytes was also done, and yielded very similar throughput results, as in graphs below (and much better random seeks: see detailed figures further below). The benchmark was repeated for a number of different read-ahead values, set using the blockdev --setra command.
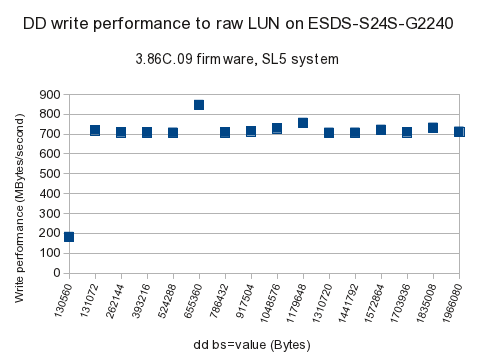
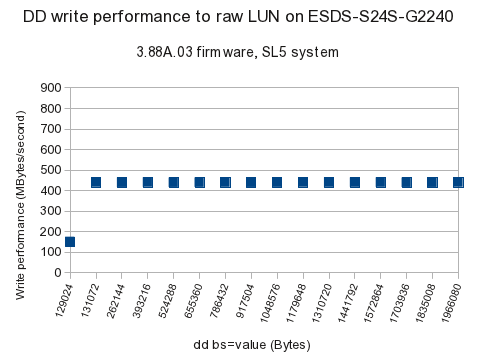
More importantly, the tests were done on two different firmwares: the earliest supplied 3.86C.09, and the latest supplied 3.88A.03. Just as with the firmware functional tests, the later firmware has signicantly lower performance, for Writes and for ReWrites (which in bonnie++ are read & modify & update in place), as seen in the graphs below.
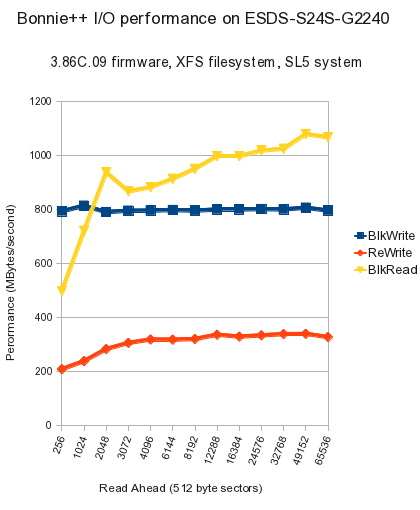
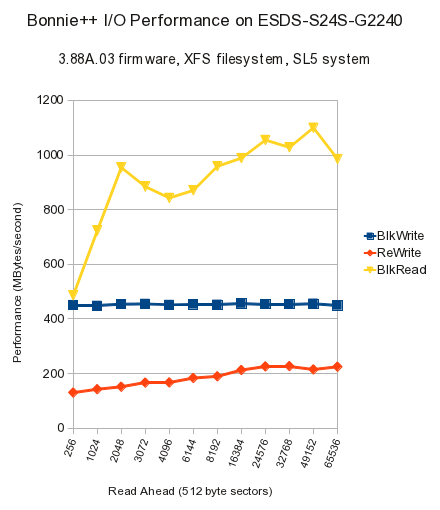
| bonnie++ | Sequential Output | Sequential Input | Random Seeks |
Sequential Create | Random Create | |||||||||||||||||||||
| Label - fstype - Read-ahead sectors | Size:Chunk Size | Per Char | Block | Rewrite | Per Char | Block | Num Files | Create | Read | Delete | Create | Read | Delete | |||||||||||||
| K/sec | % CPU | K/sec | % CPU | K/sec | % CPU | K/sec | % CPU | K/sec | % CPU | / sec | % CPU | / sec | % CPU | / sec | % CPU | / sec | % CPU | / sec | % CPU | / sec | % CPU | / sec | % CPU | |||
| 3.86C.09 firmware | ||||||||||||||||||||||||||
| Server RAM 4GB, system SL5.8 | ||||||||||||||||||||||||||
| f24a-xfs-256 | 24G:128k | 93699 | 99 | 753082 | 56 | 228929 | 20 | 85190 | 98 | 500701 | 29 | 220.7 | 1 | 256:1000:1000/256 | 4468 | 83 | 183229 | 92 | 2691 | 24 | 4284 | 77 | 149813 | 94 | 1890 | 22 |
| f24a-xfs-1024 | 24G:128k | 93662 | 99 | 719608 | 54 | 261176 | 17 | 86466 | 99 | 721256 | 28 | 222.8 | 1 | 256:1000:1000/256 | 4409 | 81 | 171990 | 94 | 2828 | 21 | 4333 | 79 | 138839 | 91 | 1817 | 19 |
| f24a-xfs-2048 | 24G:128k | 93716 | 99 | 738940 | 55 | 344821 | 23 | 86866 | 99 | 958657 | 36 | 249.2 | 2 | 256:1000:1000/256 | 4401 | 79 | 164072 | 89 | 2790 | 21 | 4291 | 78 | 141116 | 94 | 1809 | 21 |
| f24a-xfs-3072 | 24G:128k | 91118 | 99 | 724823 | 53 | 346578 | 23 | 85928 | 99 | 879979 | 31 | 244.5 | 2 | 256:1000:1000/256 | 4459 | 81 | 177398 | 91 | 2674 | 19 | 4372 | 80 | 160499 | 93 | 1823 | 19 |
| f24a-xfs-4096 | 24G:128k | 92499 | 99 | 724988 | 53 | 358242 | 24 | 87021 | 99 | 904708 | 31 | 236.0 | 2 | 256:1000:1000/256 | 4429 | 80 | 184138 | 97 | 2710 | 18 | 4336 | 79 | 160925 | 97 | 1821 | 20 |
| f24a-xfs-6144 | 24G:128k | 94019 | 99 | 706629 | 53 | 363754 | 25 | 87054 | 99 | 909374 | 33 | 223.9 | 1 | 256:1000:1000/256 | 4446 | 80 | 171604 | 90 | 2732 | 21 | 4193 | 78 | 152173 | 94 | 1811 | 19 |
| f24a-xfs-8192 | 24G:128k | 93925 | 99 | 700699 | 52 | 369985 | 26 | 86976 | 99 | 946571 | 34 | 220.8 | 1 | 256:1000:1000/256 | 4420 | 81 | 177830 | 93 | 2780 | 19 | 4347 | 80 | 158481 | 94 | 1784 | 25 |
| f24a-xfs-12288 | 24G:128k | 93649 | 99 | 726538 | 54 | 372304 | 28 | 85879 | 99 | 953598 | 36 | 240.0 | 2 | 256:1000:1000/256 | 4428 | 81 | 163393 | 92 | 2818 | 20 | 4369 | 78 | 154795 | 98 | 1807 | 19 |
| f24a-xfs-16384 | 24G:128k | 93629 | 99 | 697905 | 53 | 391535 | 30 | 84333 | 99 | 1055735 | 40 | 242.5 | 2 | 256:1000:1000/256 | 4406 | 79 | 183059 | 89 | 2811 | 20 | 4329 | 79 | 158463 | 96 | 1865 | 22 |
| f24a-xfs-24576 | 24G:128k | 93571 | 99 | 720233 | 54 | 413144 | 32 | 86625 | 99 | 1099617 | 43 | 251.3 | 2 | 256:1000:1000/256 | 4396 | 80 | 169099 | 92 | 2664 | 19 | 4343 | 79 | 147008 | 94 | 1805 | 19 |
| f24a-xfs-32768 | 24G:128k | 93871 | 99 | 705061 | 52 | 394580 | 31 | 86503 | 99 | 1025286 | 41 | 227.7 | 2 | 256:1000:1000/256 | 4402 | 81 | 167995 | 92 | 2818 | 19 | 4348 | 79 | 143667 | 93 | 1756 | 25 |
| f24a-xfs-49152 | 24G:128k | 90897 | 99 | 709804 | 52 | 374624 | 30 | 85456 | 99 | 977221 | 39 | 240.0 | 2 | 256:1000:1000/256 | 4437 | 80 | 174153 | 94 | 2865 | 22 | 4291 | 79 | 143633 | 92 | 1769 | 26 |
| f24a-xfs-65536 | 24G:128k | 93991 | 99 | 724600 | 55 | 322512 | 26 | 85460 | 99 | 981773 | 39 | 240.7 | 2 | 256:1000:1000/256 | 4423 | 80 | 173464 | 93 | 2716 | 19 | 4320 | 80 | 134330 | 97 | 1781 | 24 |
| Server RAM 24GB, system SL5.8 | ||||||||||||||||||||||||||
| f24a-xfs-256 | 48G:8k | 94254 | 99 | 774048 | 60 | 202967 | 21 | 82834 | 95 | 485328 | 29 | 457.0 | 1 | 256:1000:1000/256 | 4466 | 85 | 166346 | 93 | 2802 | 25 | 4472 | 82 | 150884 | 93 | 1913 | 23 |
| f24a-xfs-1024 | 48G:8k | 94108 | 99 | 794384 | 61 | 231994 | 18 | 84806 | 97 | 703530 | 30 | 451.0 | 0 | 256:1000:1000/256 | 4543 | 84 | 139385 | 88 | 2608 | 20 | 4371 | 81 | 141458 | 91 | 1908 | 23 |
| f24a-xfs-2048 | 48G:8k | 93973 | 99 | 771245 | 60 | 275743 | 22 | 85862 | 99 | 915364 | 36 | 413.8 | 0 | 256:1000:1000/256 | 4445 | 83 | 171772 | 99 | 2747 | 20 | 4443 | 81 | 138834 | 92 | 1744 | 25 |
| f24a-xfs-3072 | 48G:8k | 93692 | 99 | 776438 | 60 | 297976 | 24 | 86681 | 99 | 846268 | 32 | 411.3 | 0 | 256:1000:1000/256 | 4462 | 83 | 168931 | 91 | 2761 | 20 | 4473 | 82 | 148739 | 94 | 1808 | 20 |
| f24a-xfs-4096 | 48G:8k | 93877 | 99 | 776838 | 61 | 310285 | 25 | 83440 | 99 | 861199 | 32 | 436.1 | 1 | 256:1000:1000/256 | 4487 | 83 | 165989 | 91 | 2705 | 19 | 4315 | 81 | 146607 | 96 | 1864 | 22 |
| f24a-xfs-6144 | 48G:8k | 93010 | 99 | 778769 | 61 | 309713 | 25 | 86677 | 99 | 891853 | 33 | 422.8 | 0 | 256:1000:1000/256 | 4460 | 82 | 162505 | 90 | 2722 | 18 | 4469 | 82 | 130174 | 91 | 1748 | 26 |
| f24a-xfs-8192 | 48G:8k | 93906 | 99 | 776682 | 60 | 312159 | 25 | 86922 | 99 | 927283 | 35 | 429.5 | 0 | 256:1000:1000/256 | 4515 | 83 | 146962 | 89 | 2669 | 24 | 4406 | 82 | 129327 | 89 | 1760 | 25 |
| f24a-xfs-12288 | 48G:8k | 93977 | 99 | 780722 | 61 | 327606 | 26 | 86413 | 99 | 973314 | 37 | 443.0 | 1 | 256:1000:1000/256 | 4522 | 83 | 157273 | 95 | 2886 | 25 | 4481 | 82 | 131015 | 89 | 1763 | 25 |
| f24a-xfs-16384 | 48G:8k | 94223 | 99 | 781069 | 61 | 320818 | 26 | 86150 | 99 | 973476 | 36 | 409.5 | 1 | 256:1000:1000/256 | 4506 | 82 | 156645 | 93 | 2801 | 28 | 4364 | 81 | 150852 | 94 | 1872 | 20 |
| f24a-xfs-24576 | 48G:8k | 94686 | 99 | 782188 | 60 | 325310 | 27 | 86373 | 99 | 993912 | 39 | 422.7 | 1 | 256:1000:1000/256 | 4449 | 82 | 162294 | 89 | 2733 | 21 | 4399 | 81 | 142837 | 99 | 1775 | 20 |
| f24a-xfs-32768 | 48G:8k | 94188 | 99 | 780898 | 61 | 329979 | 27 | 86029 | 99 | 1000339 | 39 | 422.2 | 0 | 256:1000:1000/256 | 4477 | 83 | 145740 | 87 | 2902 | 29 | 4266 | 81 | 149848 | 94 | 1910 | 23 |
| f24a-xfs-49152 | 48G:8k | 89586 | 99 | 787245 | 61 | 330876 | 27 | 85939 | 99 | 1053784 | 41 | 426.1 | 0 | 256:1000:1000/256 | 4518 | 83 | 140554 | 86 | 2679 | 27 | 4402 | 80 | 138853 | 93 | 1910 | 23 |
| f24a-xfs-65536 | 48G:8k | 94275 | 99 | 776982 | 61 | 319123 | 28 | 85655 | 99 | 1041650 | 41 | 411.3 | 1 | 256:1000:1000/256 | 4468 | 83 | 163225 | 92 | 2661 | 20 | 4517 | 82 | 148760 | 96 | 1903 | 22 |
| 3.88A.03 firmware | ||||||||||||||||||||||||||
| Server RAM 4GB, system SL5.8 | ||||||||||||||||||||||||||
| f24a-xfs-256 | 24G:128k | 95117 | 99 | 407386 | 32 | 154869 | 13 | 85065 | 98 | 497751 | 29 | 222.5 | 1 | 256:1000:1000/256 | 4288 | 86 | 162509 | 91 | 2802 | 19 | 4288 | 80 | 153560 | 99 | 1802 | 19 |
| f24a-xfs-1024 | 24G:128k | 93609 | 99 | 400764 | 32 | 161831 | 11 | 86482 | 99 | 716641 | 29 | 219.8 | 1 | 256:1000:1000/256 | 4308 | 83 | 159870 | 90 | 2714 | 22 | 4135 | 79 | 147742 | 92 | 1915 | 21 |
| f24a-xfs-2048 | 24G:128k | 93560 | 99 | 396453 | 32 | 175796 | 13 | 86491 | 99 | 952855 | 34 | 224.5 | 1 | 256:1000:1000/256 | 4318 | 83 | 156331 | 92 | 2648 | 20 | 4136 | 80 | 146044 | 93 | 1760 | 23 |
| f24a-xfs-3072 | 24G:128k | 93679 | 99 | 403634 | 32 | 191536 | 14 | 87295 | 99 | 901502 | 31 | 219.7 | 1 | 256:1000:1000/256 | 4303 | 83 | 175406 | 92 | 2907 | 22 | 4277 | 81 | 139228 | 92 | 1794 | 20 |
| f24a-xfs-4096 | 24G:128k | 93584 | 99 | 400054 | 32 | 199999 | 14 | 86902 | 99 | 913238 | 32 | 221.5 | 2 | 256:1000:1000/256 | 4299 | 83 | 158587 | 92 | 2695 | 22 | 4224 | 80 | 147657 | 91 | 1824 | 21 |
| f24a-xfs-6144 | 24G:128k | 90376 | 99 | 409338 | 33 | 218409 | 16 | 86838 | 99 | 937351 | 34 | 228.0 | 2 | 256:1000:1000/256 | 4236 | 82 | 156689 | 97 | 2831 | 27 | 4254 | 81 | 149628 | 96 | 1790 | 19 |
| f24a-xfs-8192 | 24G:128k | 95350 | 99 | 407472 | 32 | 227140 | 16 | 84688 | 99 | 990048 | 33 | 243.5 | 2 | 256:1000:1000/256 | 4310 | 83 | 181961 | 100 | 2779 | 18 | 4205 | 80 | 136866 | 96 | 1742 | 26 |
| f24a-xfs-12288 | 24G:128k | 93100 | 99 | 396101 | 32 | 232596 | 17 | 86187 | 99 | 976075 | 34 | 232.8 | 2 | 256:1000:1000/256 | 4319 | 83 | 165680 | 96 | 2728 | 23 | 4197 | 80 | 154082 | 98 | 1794 | 19 |
| f24a-xfs-16384 | 24G:128k | 95297 | 99 | 403866 | 32 | 241401 | 18 | 84490 | 99 | 1000389 | 38 | 245.7 | 2 | 256:1000:1000/256 | 4310 | 82 | 167992 | 91 | 2653 | 19 | 4224 | 81 | 139167 | 93 | 1878 | 21 |
| f24a-xfs-24576 | 24G:128k | 94488 | 99 | 399640 | 32 | 244820 | 23 | 86224 | 99 | 1011849 | 37 | 222.4 | 1 | 256:1000:1000/256 | 4314 | 82 | 168622 | 92 | 2858 | 20 | 4220 | 80 | 158095 | 91 | 1810 | 20 |
| f24a-xfs-32768 | 24G:128k | 93206 | 99 | 406386 | 32 | 251109 | 27 | 87407 | 99 | 1042300 | 42 | 222.3 | 2 | 256:1000:1000/256 | 4335 | 82 | 166068 | 91 | 2855 | 22 | 4222 | 81 | 159078 | 96 | 1897 | 21 |
| f24a-xfs-49152 | 24G:128k | 93530 | 99 | 418691 | 33 | 242485 | 28 | 84820 | 99 | 1117555 | 45 | 253.4 | 2 | 256:1000:1000/256 | 4326 | 83 | 179460 | 91 | 2663 | 18 | 4240 | 81 | 147867 | 92 | 1927 | 22 |
| f24a-xfs-65536 | 24G:128k | 93598 | 99 | 398992 | 32 | 242670 | 32 | 86150 | 99 | 1022426 | 41 | 220.1 | 1 | 256:1000:1000/256 | 4304 | 82 | 157104 | 92 | 2703 | 20 | 4254 | 82 | 146136 | 93 | 1793 | 22 |
| Server RAM 24GB, system SL5.8 | ||||||||||||||||||||||||||
| f24a-xfs-256 | 48G:8k | 94046 | 99 | 439713 | 37 | 127076 | 13 | 82016 | 95 | 474475 | 30 | 419.4 | 0 | 256:1000:1000/256 | 4513 | 87 | 157659 | 92 | 2630 | 20 | 4419 | 82 | 149223 | 89 | 1782 | 20 |
| f24a-xfs-1024 | 48G:8k | 82296 | 99 | 436931 | 36 | 139123 | 10 | 83612 | 99 | 706040 | 30 | 411.5 | 0 | 256:1000:1000/256 | 4348 | 84 | 175706 | 90 | 2632 | 18 | 4353 | 84 | 153184 | 89 | 1745 | 24 |
| f24a-xfs-2048 | 48G:8k | 94148 | 99 | 443165 | 37 | 147960 | 11 | 85978 | 98 | 931874 | 36 | 426.7 | 1 | 256:1000:1000/256 | 4380 | 84 | 168262 | 91 | 2759 | 19 | 4374 | 84 | 146513 | 92 | 1854 | 23 |
| f24a-xfs-3072 | 48G:8k | 93124 | 99 | 444158 | 37 | 162715 | 13 | 83879 | 99 | 863548 | 33 | 436.7 | 0 | 256:1000:1000/256 | 4369 | 85 | 171697 | 95 | 2959 | 28 | 4200 | 82 | 153267 | 92 | 1796 | 21 |
| f24a-xfs-4096 | 48G:8k | 94316 | 99 | 440390 | 37 | 163334 | 12 | 86376 | 99 | 822965 | 30 | 412.0 | 0 | 256:1000:1000/256 | 4482 | 82 | 175522 | 99 | 2779 | 20 | 4405 | 81 | 152167 | 91 | 1807 | 20 |
| f24a-xfs-6144 | 48G:8k | 92935 | 99 | 442589 | 38 | 179166 | 14 | 86540 | 99 | 849937 | 31 | 409.8 | 1 | 256:1000:1000/256 | 4397 | 85 | 156574 | 95 | 2619 | 18 | 4296 | 82 | 141893 | 91 | 1889 | 23 |
| f24a-xfs-8192 | 48G:8k | 93867 | 99 | 441108 | 38 | 185113 | 14 | 86832 | 99 | 936235 | 35 | 400.8 | 0 | 256:1000:1000/256 | 4352 | 85 | 147465 | 90 | 2626 | 19 | 4295 | 83 | 152996 | 89 | 1801 | 24 |
| f24a-xfs-16384 | 48G:8k | 94131 | 99 | 445360 | 38 | 207744 | 16 | 86413 | 99 | 965398 | 36 | 423.9 | 0 | 256:1000:1000/256 | 4424 | 85 | 160430 | 90 | 2751 | 25 | 4238 | 82 | 146523 | 91 | 1802 | 21 |
| f24a-xfs-24576 | 48G:8k | 94265 | 99 | 443105 | 37 | 220534 | 21 | 85750 | 99 | 1030098 | 40 | 425.8 | 0 | 256:1000:1000/256 | 4428 | 85 | 155491 | 89 | 2624 | 20 | 4358 | 83 | 154132 | 89 | 1746 | 25 |
| f24a-xfs-32768 | 48G:8k | 91836 | 99 | 443039 | 38 | 221638 | 26 | 84924 | 99 | 1003702 | 39 | 419.6 | 0 | 256:1000:1000/256 | 4422 | 84 | 161649 | 91 | 2624 | 20 | 4371 | 83 | 149410 | 91 | 1730 | 25 |
| f24a-xfs-49152 | 48G:8k | 94183 | 99 | 444795 | 38 | 209690 | 28 | 85696 | 99 | 1074078 | 42 | 421.4 | 1 | 256:1000:1000/256 | 4430 | 85 | 163886 | 90 | 2777 | 20 | 4263 | 82 | 151927 | 94 | 1912 | 23 |
| f24a-xfs-65536 | 48G:8k | 82137 | 99 | 438685 | 37 | 219511 | 31 | 83081 | 99 | 961996 | 38 | 400.2 | 0 | 256:1000:1000/256 | 4335 | 85 | 169424 | 98 | 2756 | 18 | 4354 | 83 | 140557 | 93 | 1758 | 25 |
| Reminder of an example good result from above | ||||||||||||||||||||||||||
| f24a-xfs-16384 | 48G:8k | 94223 | 99 | 781069 | 61 | 320818 | 26 | 86150 | 99 | 973476 | 36 | 409.5 | 1 | 256:1000:1000/256 | 4506 | 82 | 156645 | 93 | 2801 | 28 | 4364 | 81 | 150852 | 94 | 1872 | 20 |
| Different raid: f26 | ||||||||||||||||||||||||||
| 3.86C.09 firmware | ||||||||||||||||||||||||||
| Server rex15 RAM 12GB, system SL6.2 | ||||||||||||||||||||||||||
| One RAID6 set on one channel, single bonnie++ | ||||||||||||||||||||||||||
| 26a-xfs-16384 | 48G:8k | 87312 | 99 | 741329 | 72 | 328550 | 38 | 82211 | 99 | 1055095 | 50 | 289.1 | 0 | 256:1000:1000/256 | 25472 | 99 | 249789 | 99 | 35369 | 99 | 24686 | 97 | 218775 | 100 | 28222 | 95 |
| Two RAID6 sets on one channel: two synched bonnie++ (sum them for total) | ||||||||||||||||||||||||||
| 26a-xfs-16384 | 48G:8k | 91007 | 99 | 326197 | 30 | 235240 | 29 | 82427 | 99 | 643803 | 33 | 258.2 | 0 | 256:1000:1000/256 | 18311 | 76 | 244922 | 99 | 23129 | 95 | 18272 | 74 | 188190 | 99 | 17942 | 93 |
| 26b-xfs-16384 | 48G:8k | 86740 | 99 | 326338 | 31 | 199821 | 25 | 81447 | 99 | 691707 | 33 | 249.8 | 0 | 256:1000:1000/256 | 18349 | 74 | 236778 | 99 | 23500 | 97 | 18069 | 76 | 186312 | 99 | 15759 | 87 |
| Two RAID6 sets on 2 separate channels, two synced bonnie++ (sum them for total) | ||||||||||||||||||||||||||
| 26a-xfs-16384 | 48G:8k | 89490 | 99 | 323747 | 31 | 185945 | 22 | 81803 | 99 | 720482 | 34 | 251.2 | 0 | 256:1000:1000/256 | 18305 | 78 | 196423 | 99 | 19967 | 93 | 17834 | 78 | 186811 | 99 | 13821 | 88 |
| 26b-xfs-16384 | 48G:8k | 90047 | 99 | 323905 | 31 | 223822 | 28 | 82524 | 99 | 672004 | 33 | 261.0 | 0 | 256:1000:1000/256 | 18750 | 79 | 229942 | 99 | 23380 | 96 | 18403 | 77 | 208329 | 99 | 13898 | 88 |
| One RAID6+0 single bonnie++ | ||||||||||||||||||||||||||
| 26a-xfs-16384 | 48G:8k | 87985 | 99 | 670186 | 66 | 364015 | 42 | 81942 | 99 | 1313013 | 62 | 314.2 | 0 | 256:1000:1000/256 | 25470 | 96 | 284672 | 99 | 35294 | 99 | 24189 | 96 | 219745 | 99 | 28142 | 96 |
| One RAID6+0 two synched bonnie++ | ||||||||||||||||||||||||||
| 26a-xfs-16384 | 48G:8k | 86618 | 99 | 339730 | 32 | 192807 | 24 | 80923 | 99 | 594828 | 29 | 236.8 | 0 | 256:1000:1000/256 | 10962 | 82 | 196467 | 99 | 12112 | 80 | 10554 | 78 | 183568 | 99 | 9568 | 76 |
| 26a-xfs-16384 | 48G:8k | 91131 | 99 | 342406 | 33 | 193377 | 24 | 79676 | 99 | 595296 | 29 | 238.0 | 0 | 256:1000:1000/256 | 10919 | 82 | 192437 | 99 | 12167 | 76 | 10549 | 81 | 177017 | 99 | 9523 | 78 |
| One RAID6+0 single bonnie++ with various read-aheads | ||||||||||||||||||||||||||
| 26a-xfs-256 | 48G:8k | 91066 | 99 | 651833 | 62 | 250033 | 31 | 80365 | 98 | 526674 | 31 | 328.9 | 0 | 256:1000:1000/256 | 25009 | 97 | 280709 | 99 | 34734 | 99 | 24763 | 97 | 230272 | 99 | 27309 | 96 |
| 26a-xfs-1024 | 48G:8k | 86843 | 99 | 738922 | 68 | 290384 | 34 | 81665 | 99 | 707247 | 34 | 346.3 | 0 | 256:1000:1000/256 | 25459 | 97 | 260823 | 99 | 32926 | 97 | 24512 | 97 | 209641 | 100 | 27447 | 96 |
| 26a-xfs-2048 | 48G:8k | 88090 | 99 | 667848 | 63 | 355722 | 40 | 82059 | 99 | 1020125 | 47 | 301.6 | 0 | 256:1000:1000/256 | 25231 | 97 | 306432 | 100 | 34218 | 99 | 24068 | 98 | 208868 | 99 | 26742 | 96 |
| 26a-xfs-4096 | 48G:8k | 86320 | 99 | 702986 | 64 | 363922 | 42 | 81775 | 99 | 1152035 | 53 | 298.6 | 0 | 256:1000:1000/256 | 25272 | 96 | 252532 | 99 | 33905 | 99 | 24013 | 98 | 229937 | 99 | 26694 | 94 |
| 26a-xfs-8192 | 48G:8k | 77634 | 99 | 649424 | 62 | 372040 | 42 | 76474 | 99 | 1254107 | 58 | 329.6 | 0 | 256:1000:1000/256 | 25119 | 97 | 308816 | 100 | 35807 | 99 | 24423 | 97 | 203230 | 99 | 26213 | 96 |
| 26a-xfs-16384 | 48G:8k | 85564 | 99 | 653308 | 60 | 363821 | 43 | 76197 | 99 | 1316425 | 62 | 340.1 | 0 | 256:1000:1000/256 | 25196 | 97 | 271375 | 99 | 35953 | 99 | 23688 | 98 | 189150 | 99 | 25213 | 95 |
| 26a-xfs-32768 | 48G:8k | 88284 | 99 | 719849 | 66 | 370491 | 41 | 83557 | 99 | 1333534 | 63 | 283.0 | 0 | 256:1000:1000/256 | 25203 | 97 | 249606 | 100 | 32702 | 96 | 24652 | 96 | 204294 | 99 | 26964 | 95 |
| 26a-xfs-65536 | 48G:8k | 89530 | 99 | 677681 | 61 | 373245 | 43 | 81955 | 99 | 1339705 | 64 | 328.5 | 0 | 256:1000:1000/256 | 25212 | 97 | 258004 | 100 | 34146 | 99 | 24536 | 97 | 233819 | 99 | 28380 | 97 |
| final set on a single logical RAID6 drive | ||||||||||||||||||||||||||
| 26a-xfs-256 | 48G:8k | 88749 | 99 | 730166 | 66 | 251617 | 31 | 79770 | 99 | 552573 | 30 | 285.7 | 0 | 256:1000:1000/256 | 26020 | 98 | 339253 | 99 | 35210 | 99 | 24984 | 98 | 242407 | 99 | 27925 | 96 |
| 26a-xfs-1024 | 48G:8k | 87167 | 99 | 773616 | 66 | 289651 | 35 | 79582 | 98 | 740045 | 34 | 302.7 | 0 | 256:1000:1000/256 | 25547 | 98 | 277077 | 99 | 32649 | 96 | 24008 | 97 | 206898 | 99 | 27335 | 96 |
| 26a-xfs-2048 | 48G:8k | 91034 | 99 | 744716 | 73 | 337799 | 39 | 80244 | 99 | 988111 | 46 | 284.6 | 0 | 256:1000:1000/256 | 25519 | 97 | 281377 | 100 | 31700 | 96 | 24695 | 97 | 233147 | 100 | 27066 | 95 |
| 26a-xfs-3072 | 48G:8k | 86817 | 99 | 742619 | 68 | 327499 | 40 | 82403 | 99 | 882648 | 41 | 300.2 | 0 | 256:1000:1000/256 | 25426 | 97 | 262265 | 100 | 31940 | 97 | 24584 | 97 | 223224 | 99 | 28067 | 96 |
| 26a-xfs-4096 | 48G:8k | 90731 | 99 | 732529 | 67 | 339832 | 38 | 81537 | 99 | 921370 | 43 | 297.2 | 0 | 256:1000:1000/256 | 25642 | 98 | 279950 | 99 | 32657 | 97 | 23742 | 98 | 230243 | 99 | 26500 | 94 |
| 26a-xfs-6144 | 48G:8k | 91508 | 99 | 704345 | 67 | 338929 | 41 | 82836 | 99 | 977529 | 45 | 280.1 | 0 | 256:1000:1000/256 | 25702 | 99 | 339588 | 99 | 31131 | 96 | 24482 | 97 | 222050 | 100 | 26424 | 95 |
| 26a-xfs-8192 | 48G:8k | 90374 | 99 | 745447 | 69 | 346980 | 38 | 75975 | 99 | 1029209 | 47 | 294.3 | 0 | 256:1000:1000/256 | 25311 | 97 | 271421 | 100 | 30969 | 96 | 24391 | 96 | 186307 | 99 | 24529 | 95 |
| 26a-xfs-12288 | 48G:8k | 89904 | 99 | 701918 | 69 | 340218 | 38 | 79619 | 99 | 1045121 | 49 | 297.8 | 0 | 256:1000:1000/256 | 25461 | 98 | 266706 | 99 | 33086 | 97 | 24120 | 97 | 208445 | 100 | 28981 | 97 |
| 26a-xfs-16384 | 48G:8k | 88960 | 99 | 727165 | 71 | 347926 | 41 | 82026 | 99 | 1052205 | 50 | 292.5 | 0 | 256:1000:1000/256 | 25471 | 98 | 267156 | 99 | 35033 | 99 | 24097 | 97 | 207177 | 99 | 27184 | 96 |
| 26a-xfs-24576 | 48G:8k | 89634 | 99 | 695188 | 63 | 344629 | 40 | 82802 | 99 | 1124647 | 53 | 282.6 | 0 | 256:1000:1000/256 | 25599 | 97 | 279385 | 100 | 31047 | 95 | 24144 | 97 | 227649 | 99 | 26739 | 95 |
| 26a-xfs-32768 | 48G:8k | 83321 | 99 | 722130 | 67 | 317217 | 39 | 82986 | 99 | 1156133 | 55 | 299.2 | 0 | 256:1000:1000/256 | 25504 | 97 | 253846 | 99 | 31864 | 95 | 24513 | 97 | 233390 | 99 | 27067 | 94 |
| 26a-xfs-49152 | 48G:8k | 91313 | 99 | 735238 | 67 | 328848 | 37 | 81636 | 99 | 1086866 | 51 | 298.5 | 0 | 256:1000:1000/256 | 25512 | 97 | 270891 | 100 | 32813 | 96 | 24799 | 98 | 234087 | 99 | 26462 | 96 |
| 26a-xfs-65536 | 48G:8k | 91379 | 99 | 701461 | 69 | 328827 | 38 | 82259 | 99 | 1110502 | 53 | 284.4 | 0 | 256:1000:1000/256 | 25635 | 98 | 265614 | 99 | 31014 | 97 | 24569 | 97 | 232559 | 99 | 27612 | 96 |
Worth noting how much sensible the XFS file create and delete time is, under RHEL6 / SL6 (result lines beginning 26a or 26b), compared with the poor XFS times in earlier RHEL5 / SL5 systems (also see my comparison of XFS and ext4 filesystems). Create time is around 6 times shorter, delete time 15 times shorter (check).
L.S.Lowe