Note: also see my most recent Infortrend RAIDs and the index.
These are some performance tests on a Infortrend EonStor RAID system, A24U-G2421-1, attached via a LSI22320RB-F scsi HBA card, also known as LSI22320-R, with file-system sizes of 1.7 TB and 7.5 TB.
I have a LSI22320RB-F card fitted in a PowerEdge 1950, and attached
to a transtec RAID (rebadged
Infortrend EonStor). The operating system is currently CentOS 5 32-bit.
See my page RAID 2 TB limit
for information on what was necessary to get this setup working with a
8TB file-system.
Also see my page
Performance tests on ext4 and xfs on an Infortrend RAID for more recent information.
blockdev --setra $rab /dev/$devwhere $rab is the read-ahead buffer size in 512-byte sectors; this was equivalent in 2.6 kernel to doing:
echo $rabkb > /sys/block/$dev/queue/read_ahead_kbwhere $rabkb is the read-ahead buffer size in kBytes. The system default is 128 kBytes.
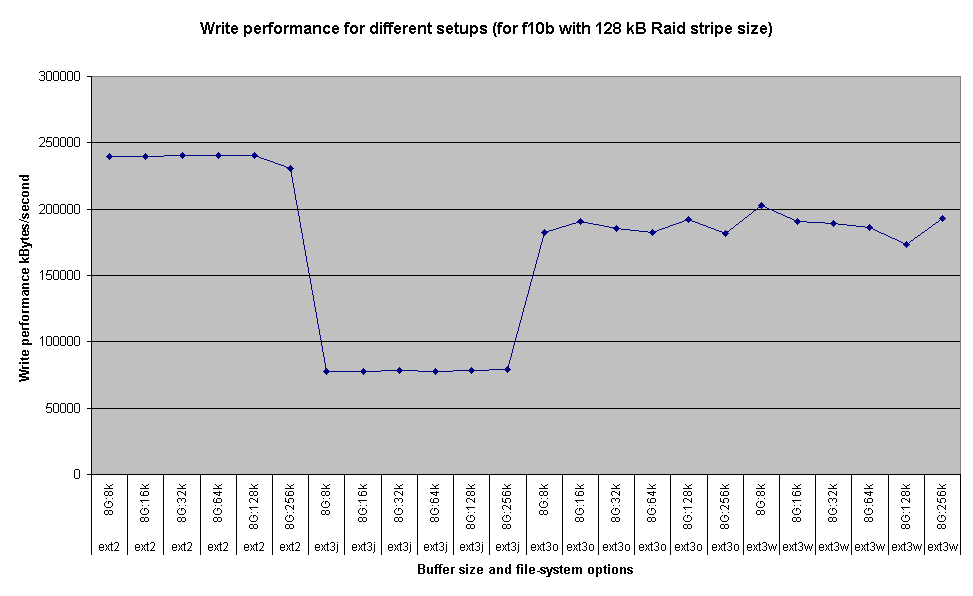
The RAID has a 1GB cache and the server has 2GB RAM. The RAID was configured for RAID-6, with a stripe-size of 256 kBytes originally, though the stripe-size was changed back to 128 kBytes (the factory default) because this performed slightly better. The bonnie++ file-size was always 8GB.
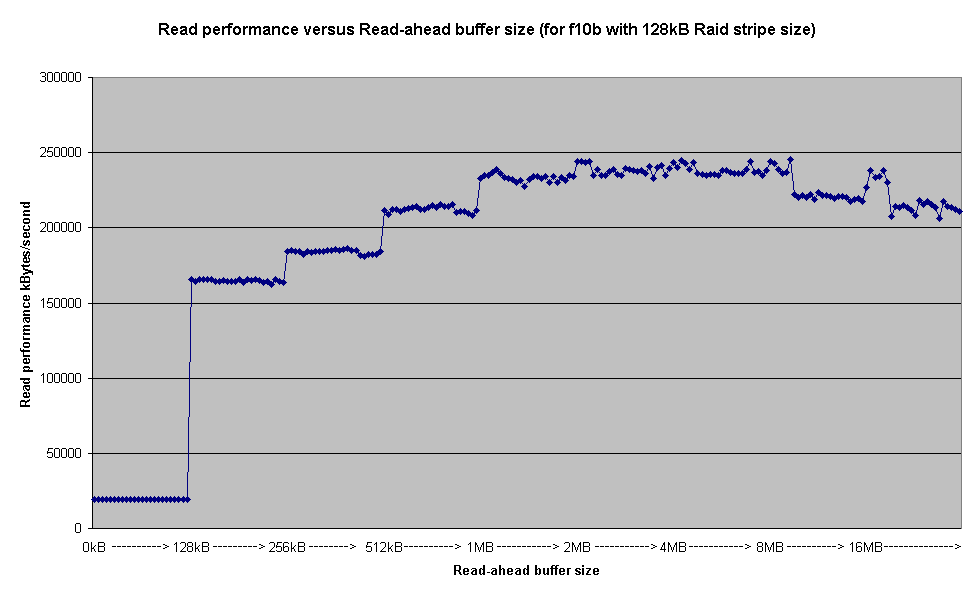
Each read-ahead buffer setting was tested with 24 variations, which is why there are 24 data points per read-ahead value: 4 different file-system setups for ext2 and ext3, and 6 different bonnie++ buffer-size settings (8kB to 256kB) within each file-system setting. It demonstrates that the read-ahead buffer size is the dominant performance determinator, and that different file-systems and options for ext2/ext3 affect the read performance hardly at all. Very large sizes of 8MB or larger have a minor adverse affect on ext3 read performance. The default read-ahead buffer size of 128 kB gives around 65% of the optimum performance, which was achieved with settings in the range 1-4 MB, so it's worth tuning this size to 1 or 2 MB. The best block read-rate was around 240 MBytes/sec.
Filesystem 1K-blocks Used Available Use% Mounted onSince we are going to put mainly large files on this filesystem, we can make do with a lot fewer inodes. Fewer inodes give me a small gain in available file-space, and reduce a full fsck time a bit (see a section below), though it's a case of diminishing returns. I settle on a bytes-per-inode of 65536, eight times the default.
/dev/sdc 7208165240 182888 7207572752 1% /disk/10b
A mkfs -t ext3 -E stride=32 -i 65536 on this 10b filesystem took 26m44s. Surprising it wasn't less than before, but there we go. Same tuning. We gain an extra 100 GB of space, for what it's worth!
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sdc 7308286072 182888 7307693584 1% /disk/10b
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sdc 7308286072 2952254708 4355621764 41% /disk/10b
The data on this disk was arranged with 3 directories each containing 1000 sub-directories each containing 1000 1MB flat-files.
The time for a journal recovery after a deliberate system crash was under 1 second, as shown:
# time fsck.ext3 /dev/sdc
e2fsck 1.39 (29-May-2006)
10b: recovering journal
10b: clean, 3003020/114423808 files, 741760799/1830768640 blocks
real 0m0.930s
user 0m0.397s
sys 0m0.077s
# date; time fsck.ext3 -p -f /dev/sdc; dateThis was re-tested for various other disk utilisations, and different max-inode settings. The results are below, sorted by time taken:
Wed Mar 28 20:04:23 BST 2007
10b: 3003020/114423808 files (6.4% non-contiguous), 741760799/1830768640 blocks
real 153m7.227s
user 1m17.915s
sys 2m3.596s
Wed Mar 28 22:37:30 BST 2007
| mkfs.ext3 -i option | used nodes | total inodes | total 4kB blocks | used blocks | timing (minutes) |
|---|---|---|---|---|---|
| 65536 | 0.0M | 114M | 1830M | 0% | 34m |
| 65536 | 1.0M | 114M | 1830M | 14% | 70m |
| 8192 | 1.0M | 915M | 1830M | 15% | 111m |
| 8192 | 2.0M | 915M | 1830M | 28% | 143m |
| 819200 | 3.0M | 9M | 1830M | 40% | 141m |
| 65536 | 3.0M | 114M | 1830M | 41% | 153m |
| 8192 | 3.0M | 915M | 1830M | 42% | 170m |
| 819200 | 4.0M | 9M | 1830M | 54% | 180m |
| 8192 | 4.0M | 915M | 1830M | 55% | 204m |
| 8192 | 5.0M | 915M | 1830M | 69% | 236m |
| 819200 | 6.0M | 9M | 1830M | 81% | 261m |
| 8192 | 6.0M | 915M | 1830M | 82% | 274m |
An important thing to do of course is to use tune2fs to set maximum mount count and check interval to suitable values, so that a full fsck is done at the system manager's convenience, not at the convenience of the system after a power-failure when you're trying to get everything back online quickly!
Also see my page Performance tests on ext4 and xfs on an Infortrend RAID for more recent information.